

最近由于不能描述的原因,很多服务器挂了……
实际上,作为技术人员,翻墙之所以为刚需,就是为了Google。
bing是残废;baidu是垃圾;唯有Google才能准确提供相关技术文档。
那么,在目前的网络环境下,如何能低风险的访问Google(节省下有关部门的茶钱)?
最近由于不能描述的原因,很多服务器挂了……
实际上,作为技术人员,翻墙之所以为刚需,就是为了Google。
bing是残废;baidu是垃圾;唯有Google才能准确提供相关技术文档。
那么,在目前的网络环境下,如何能低风险的访问Google(节省下有关部门的茶钱)?
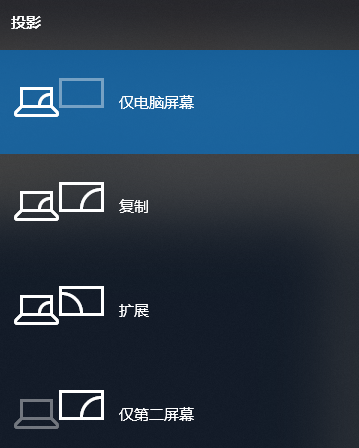
最近更换了dell显示器后,发现Intel的HD4000显卡在多显示器的情况下,偶尔会跳动。
很烦,不过也没必要换显卡,毕竟第二显示器只是在调试的时候才会用到,平时都是关闭。
不过,作为懒蛋,俺并不喜欢到系统自带的显示配置里面去关闭显示器。
于是,可以使用这个工具:displayswitch.exe

shuf , GNU命令集中的一员。一般用来对输入数据进行随机排序。(和sort –random-sort很像)。
例子:
|
|
PS:偶尔看看info coreutils 挺长见识的。
AI的“凝视” :DeepWarp: Photorealistic Image Resynthesis for Gaze Manipulation
很好玩。
好吧,我承认这篇文章主要是为了测试插入mp4视频。
![]()
在虚拟主机的模式下,certbot在生成www子域名的时候,会出现问题。
原来的向导类的方法选择后,会造成www子域名使用根域名的证书,从而出错。
如果出现问题,可以这么操作:
将原本的向导自选的脚本:
|
|
改为强制指定域名:
|
|
certbot提示是否重新验证,同意即可。

最近在搞一个采集站。用wordpress实现展示。
一番爬虫采集后,用python post到wordpress的草稿箱中。
问题来了,每次审核发布的时候,发布时间竟然是以进草稿箱为准。

这不能忍啊。每次审核发布后,时间都得手动调整,太累。
方法很多种,这里用最简单的。

在箭头的地方输入以下js代码:
|
|
这样,发布前点击下这个书签,时间就改成当前时间了。
PS:为啥一个嵌入式工程师懂这个????

入门向的帖子。给某人的教程。
首先是python爬虫脚本。注意,里面有输入日志,用来保留图片的url。
没加什么异常容错,就是单纯的原理脚本。
|
|
然后,用crontab -e 来添加一个日常任务。每天凌晨1:30分跑起来:
|
|
Bingo~

