
多年不动手,CPU啥行情是完全不懂了。
查查性能,找找性价比,也就依靠这种天梯榜了。

SQLite的python自带接口里面,是没有在线备份功能的。
所以,一般来说,备份方案使用这种方式:
|
|
大概的核心,也是使用connection的iterdump功能。
不过,如果引用一个库,sqlitebck,使用起来会简单很多。
|
|
调用接口:
|
|
另,为了提高性能,sqlite的内存数据库名字,可以使用保留的:memory:
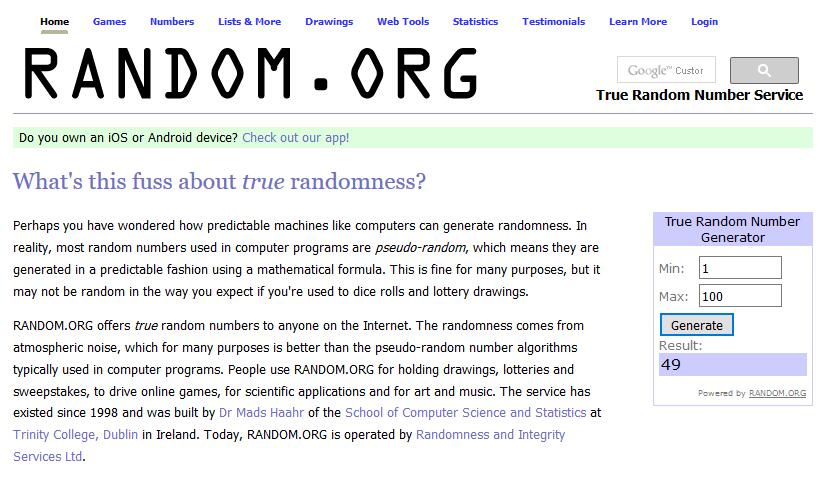
一般编程,使用的随机数大多是伪随机。Random.org提供在线的真随机数服务。
种类很多,大致说说:
网络获取也比较简单:
|
|
当然,也可以用比较正规的api服务:api.random.org
估计到今年(2017)年中收费。
PS:年会抽奖就用这个东西。保证公平公正。(网站提供数字签名服务,铁证)
看看吧,如果是使用phantomjs的话,就需要多加一些点击事件。
|
|
用python的requests的话,就需要在post里面,添加新字段。
|
|
requests访问https网站的时候,如果证书出现问题,会raise出来异常。
其实,做爬虫的,还在乎啥证书,安不安全呗。
一般,会在requests的getorpost方法里面加入:
|
|
形如:
|
|
不过,这样就意味着requests可能会出现warning。
|
|
warning 是意外的日志数据,多了很讨厌。
利用下面的方法关闭:
|
|
PS:这种情况一般是探测到了中间人攻击。如果使用动态代理,出现类似warning的时候,最好去掉这个代理(他在抓你的https数据)

这个导出cookie还是蛮好用的。
和python配合,需要到处LWP 类型的Cookie,然后python使用cookielib库。
|
|
cookies,要符合cookielib的模式。这里,貌似有个字符串规则。
|
|
magic_re的规则是:
|
|
也就是说,cookie文件的格式,第一行需要是这样的:
|
|
老实说,比较烂。用editthiscookie导出后,要修改头一下。

Performance->setting
|
|
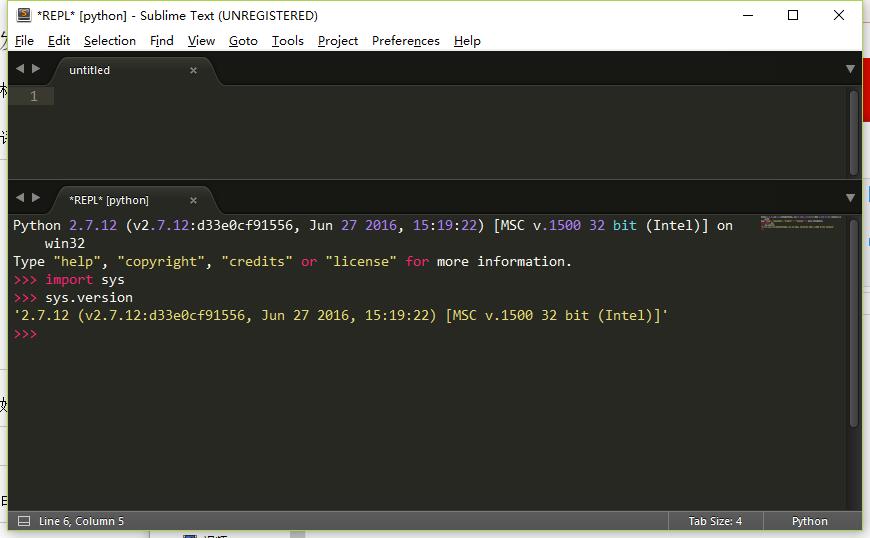
Sublime Text是很好用的温变编辑器。其中,有个插件可以说是IDLE的最佳替代品。
Sublime Text REPL 快速,好用的python shell
利用这个,可以快速实验代码,调试程序。
/pinout.jpg)